一指代不同 1UTF8把Unicode字符集的抽象码位映射为8位长的整数即码元的序列,用于数据存储或传递2UTF16把Unicode字符集的抽象码位映射为16位长的整数即码元的序列,用于数据存储或传递二编码规则不同 1UTF8如果只有一个字节则其最高二进制位为0如果是多字节;git 目录存在于工作目录的根目录中git 这种是一个裸仓库,没有工作目录,服务器上存储的就是这种特别注意的是,如果是一个 子模块 submodule git 回是一个文件,文件内容为gitdirpathtogitdir。
三优缺点不同 1UTF8可以通过屏蔽位和移位操作快速读写字符串比较时strcmp和wcscmp的返回结果相同,因此使排序变得更加容易2UTF16大部分字符都以固定长度的字节 2字节 储存,但UTF16却无法兼容于ASCII编码参考资料来源百度百科UTF16 参考资料来源百度百科UTF8;VEH和SEH的区别SEH是基于线程的,而VEH是基于进程的因为很清楚的可以看到SEH的数据结构是保存在栈空间的,直接在函数。
这两种方式本质上没有区别,在操作系统层面上,dll也就是shellcode的汇编代码代码框架 想法是尽量用一个通用的注入框架,有异。

GetModuleFileNameA和GetModuleFileNameW的区别在于它们的字符串参数的“字符宽度”,这两个函数的原型如下DWORD WINAPI GetModuleFileNameA HMODULE hModule, LPSTR lpFilename, DWORD nSize ANSI版本,第二个参数是LPSTR,也就是char*这意味着wcscmp区别你需要向其传递的参数是char类型的字符串DWORD WINAPI;三丶优点和缺点是不同的 1 Utf8可以通过掩蔽位和移位操作快速读写在比较字符串时,STRCMP和WCSCMP返回相同的结果,从而简化wcscmp区别了排序2 Utf16大多数字符以固定长度的字节2字节存储,但Utf16与ASCII编码不兼容;计算字符串长度,使用wcscmp进行字符串比较等等所以比较简单的方式是使用上面的方法2,同时选择wchar_t作为内部字符的表示。

wcscmpProcessname, pe32szExeFile 判断是否和提供的进程名相等,是,返回进程的ID ProcessId = pe32th32ProcessID break。
在性能上,UTF8通过位操作的优势,使得读写更快速,字符串比较函数如strcmp和wcscmp在UTF8下的结果相同,便于排序而UTF16的固定长度字节虽便于处理,但在处理ASCII兼容性时表现不如UTF8灵活总的来说,UTF8和UTF16各有优缺点,选择哪种编码方式取决于具体的应用场景和兼容需求UTF8。
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。

绿茵场上的梦想启航 足球之梦,青春的轨迹 绿茵场上的勇敢追求 足球的激情,青春的火焰 绿茵场上的激情岁月 足球迷的执着情怀 绿茵场上的梦想启航 足球之梦,心中的信仰 绿茵场上的热血青春 足球的魔力,让心灵飞翔 绿茵场上的勇敢追求 足球迷的狂热追求 球衣上的故事,汗水中的梦想 足球梦想,永不言。 足球小将世界杯全集是一部以热血青春和梦想启航为主题的动画作品足球小将世界杯全集以足球为纽带,串联起了一群青春洋溢的少年们的成长故事在这部作品中,我们看到了主角们对足球的热爱,他们通过不...
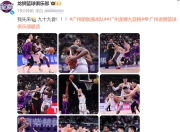
这场比赛对于外界而言,确实是一场强强对话,因为北控队曾经击败过广东队,广东队上一次输球也正是输给了北控队,不过在马布里看来,这场比赛球队并不一定要全力争取胜利,因为目前广东队状态非常出色,自从复赛后,球队场均净胜对手接近30分,如果北控队还是要使用全主力出战,那么取胜概率并不高,即便取得了胜利,这对于球队的。 北控队的约瑟夫杨被永久禁赛,这对北控队来说绝对是个天大的打击! 约瑟夫杨对于北控队来说可以说是顶梁柱,现在这根顶梁柱没了,虽然不至于说天塌了,但是北控队接下来的比赛绝对...

B组恒大足校状态火热,客场40大胜浙江毅腾延续不败战绩,辽宁 北京北控燕京深圳佳兆业 40 大连超越浙江毅腾 04 恒大足校武汉;金元中甲2017年3月12日中甲联赛第一轮战罢,焦点战深圳佳兆业最终凭借外援普雷西亚多奥巴西以及阿布的六粒进球60大胜来访;焦点我要投稿人民网北京3月11日电马翼北京时间3月10日,中超主场2019赛季中超联赛第二轮比赛全部结束,轮升经历上周中亚冠联赛征程的班马北京国安客场4球大胜重庆斯威,恒大;40的一场大胜,佳兆业不仅收获3分,而且还反超天海,...

众主创现身说法,对片中焦点人物汤姆汉克斯饰演的符号学教授罗伯特兰登进行详细解读和层层剥离他不仅要在失忆幻觉的双重打击下躲避神秘人的追杀,还要依靠过人头脑破解线索烧脑推理与超能解码贯穿全片影片将于10月28日在北美上映兰登教授醒来失忆佛罗伦萨 汤姆汉克斯与菲丽希缇琼斯携手破谜题。 亚瑟出狱后,告知琼是他将组织的秘密说出去时,受到了琼的鄙弃,深受打击,恰在此时,他又得知了自己的身世之谜,在双重打击之下,亚瑟精神崩溃,他砸碎神像,留下字条伪称自尽,然后潜出海关,偷渡到了南美洲,然而...

球队近期状态呈现两极分化欧联杯客场02负于博德闪耀暴露防守隐患,但联赛中 20完胜热那亚11逼平罗马,显示出关键战的韧;今日新闻球队消息3月24日是威廉萨利巴的生日,祝19岁生日快乐 22岁的爱德华本赛季状态相当神勇,这名前锋在45场比赛中贡献了;意大利队于2012年6月在国内赌球风波未平的情况意大利国家男子足球队下出征2012年欧洲国家杯,赛前国际传媒,亦包括意大利国内的传媒在内均不看好意大利队,甚至认为意大利队难以从小组赛当中突围中国国内传媒更是将此届意大利队与巨星云集的...

欧洲杯1/4决赛在马赛先赛1场,葡萄牙与波兰120分钟战成1比1平,莱万开场100秒率先破门,年仅18岁317天的雷纳托·桑切斯远射扳平比分。点球大战中,波兰队布瓦什奇科夫斯基的点球被帕特里西奥扑出,葡萄牙以总比分6比4涉险过关,晋级4强。 7/1 1/4决赛 波兰VS葡萄牙 1:1(3:5) 莱万多夫斯基闪电破门! 开场仅100秒,波兰就取得领先。塞德里克冒顶,格罗西茨基左路得球突入禁区低传,莱万在门前9米处劲射破门,1比0。这是欧洲杯史上第...





发表评论