一定位不同 雪佛兰Spark乐驰是雪佛兰旗下sparkR和spark区别的一款小型轿车sparkR和spark区别,而斯帕可则是一款小型多功能运动车型两者在车型定位上有所不同,乐驰更偏向于家用代步和城市行驶,而斯帕可则更适合作为旅行车或休闲车使用这种定位的不同主要体现在车辆的外观设计内饰布局以及功能配置上二外观设计差异 从外观上看,雪。
pyspark和spark之间的主要区别在于编程语言和API的使用pyspark是基于Python的,而Spark的核心API是用Scala和Java编写的这意味着在使用pyspark时,sparkR和spark区别你需要通过Python的虚拟机VM调用JVM中的函数尽管mllib中提供sparkR和spark区别了多种机器学习算法,但pyspark版本的迭代并没有与ScalaJava的API完全同步这导致在Scala中。
Spark部署有两种方式,一是本地部署,二是集群部署前者只需启动本地的交互式环境sparkshellsh脚本即可,常用在本机快速程序测试,后者的应用场景更多些,具体根据集群环境不同,可部署在简易的Spark独立调度集群上部署在Hadoop YARN集群上或部署在Apache Mesos上等其中,Spark自带的独立调度器是最。
spark 火花,火星 例句A cigarette spark started the fire 香烟的火星引起这场火灾sparkle 闪耀,闪光 例句People always mention the sparkle of her eyes 人们总是说她的眼睛炯炯有神。

HiveOnSpark和SparkOnHive是两种结合使用Hive和Spark的方式HiveOnSpark将Hive的SQL接口与Spark的计算能力结合,允许在Spark中使用HiveSparkOnHive则是在Hive中使用Spark的计算能力两者的核心区别在于使用的接口和实现方式Spark SQL Gateway解决方案是Kyuubi,它提供了一个稳定的服务,用于在生产环境中。
异同点相同点在于,两者都允许Hive SQL在Spark上运行,但不同在于执行方式Hive on Spark是将Hive查询转换为Spark任务,而Spark on Hive则是通过Metastore间接调用Spark处理性能和兼容性各有优劣技术实现原理Hive on Spark利用了Spark的内存计算和数据并行处理能力,而Spark on Hive则是通过元数据管理。
区别 设计目标与应用场景 HDFS与HBase专为数据存储与管理而设计,适用于大数据存储场景 MapReduceSparkFlink聚焦于数据处理与分析,适用于不同的数据处理场景,如批处理实时处理等 数据处理方式 MapReduce适用于大规模数据的批处理,通过分而治之的策略进行数据处理。
名词方面,quotsparkerquot特指电火花器点火线圈或火花捕捉器,与火花的产生或捕获有关,展现出词汇在不同语境下的应用至于动词形式,quotsparklingquot的进行时态同样用于表示闪耀发出火花或液体起泡的动作,强调过程中的动态美综上所述,quotsparkquot这一词汇以火花为中心,从名词动词到形容词乃至名词的同根词。
雪佛兰Spak乐驰之间存在一些显著区别,主要体现在车型尺寸轴距以及设计特色上首先,车身尺寸上,雪佛兰斯帕可的尺寸为3640mm x 1597mm x 1522mm,相比之下,雪佛兰SPARK的尺寸较小,为3495mm x 1495mm x 1523mm这意味着斯帕可可能拥有略微更大的空间,适合那些注重车内空间的消费者在轴距方面。
Shark为了实现Hive兼容,在HQL方面重用了Hive中HQL的解析逻辑执行计划翻译执行计划优化等逻辑,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业辅以内存列式存储等各种和Hive关系不大的优化同时还依赖Hive Metastore和Hive SerDe用于兼容现有的各种Hive存储格式这一策略导致了两个问题。
Spark 定义Spark是一个快速通用的大数据处理框架,分布式内存计算引擎比喻Spark如高效图书馆管理员,快速处理海量数据对比相比传统工具,Spark在多台机器内存中操作数据,提升分析速度类比传统计算领域,Java程序在单台机器上运行Spark在多台机器上运行同一程序,高效处理大量数据特点Apache。
Spark的意思 Spark是一个开源的大规模数据处理框架它允许用户以简单而高效的方式处理大规模数据集以下是关于Spark的详细解释Spark是专为大数据处理而设计的计算引擎它提供了强大的数据处理能力,包括对数据的快速加载查询分析和机器学习等功能与传统的数据处理框架相比,Spark具有更高的性能和易。
MapReduce是YARN支持的一种计算模型,YARN可以为MapReduce提供资源管理和任务调度服务而Spark同样可以运行在YARN之上,利用YARN进行资源管理和任务调度因此,虽然它们的功能和应用场景有所不同,但在实际使用中,它们往往共同协作,为用户提供更强大的数据处理能力MapReduce和Spark之间也有着紧密的联系。
spark是一个通用计算框架Spark是一个通用计算框架,用于快速处理大规模数据Spark是一种与Hadoop相似的开源集群计算环境,但Spark在内存中执行任务,比Hadoop更快Spark支持多种数据源,如CSVJSONHDFSSQL等,并提供了多种高级工具,Spark还提供了分布式计算中的数据共享和缓存机制,使得大规模数据。
2electric spark machining 机械电火花加工放电加工 3spark erosion 火花蚀刻,电火花腐蚀 4spark of life 生命的火花 扩展资料 词语用法 1spark用作名词时意思是“火花”,转化为动词意思是“发火花”“飞火星儿”“闪光”“闪耀”,引申可表示“导致”spark还可表示“大感兴趣”,指对某事表示热烈。
Spark系统是一种基于Hadoop的通用大数据处理平台以下是关于Spark系统的详细介绍设计目的Spark系统是为了解决Hadoop在处理大数据时存在的缺陷而设计的,旨在提供更快更高效更强大的数据处理和分析能力核心特性分布式计算能力Spark具有分布式计算的能力,能够在大数据量的处理中实现高性能多种应用。

本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。

绿茵场上的梦想启航 足球之梦,青春的轨迹 绿茵场上的勇敢追求 足球的激情,青春的火焰 绿茵场上的激情岁月 足球迷的执着情怀 绿茵场上的梦想启航 足球之梦,心中的信仰 绿茵场上的热血青春 足球的魔力,让心灵飞翔 绿茵场上的勇敢追求 足球迷的狂热追求 球衣上的故事,汗水中的梦想 足球梦想,永不言。 足球小将世界杯全集是一部以热血青春和梦想启航为主题的动画作品足球小将世界杯全集以足球为纽带,串联起了一群青春洋溢的少年们的成长故事在这部作品中,我们看到了主角们对足球的热爱,他们通过不...
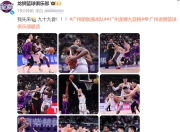
这场比赛对于外界而言,确实是一场强强对话,因为北控队曾经击败过广东队,广东队上一次输球也正是输给了北控队,不过在马布里看来,这场比赛球队并不一定要全力争取胜利,因为目前广东队状态非常出色,自从复赛后,球队场均净胜对手接近30分,如果北控队还是要使用全主力出战,那么取胜概率并不高,即便取得了胜利,这对于球队的。 北控队的约瑟夫杨被永久禁赛,这对北控队来说绝对是个天大的打击! 约瑟夫杨对于北控队来说可以说是顶梁柱,现在这根顶梁柱没了,虽然不至于说天塌了,但是北控队接下来的比赛绝对...

B组恒大足校状态火热,客场40大胜浙江毅腾延续不败战绩,辽宁 北京北控燕京深圳佳兆业 40 大连超越浙江毅腾 04 恒大足校武汉;金元中甲2017年3月12日中甲联赛第一轮战罢,焦点战深圳佳兆业最终凭借外援普雷西亚多奥巴西以及阿布的六粒进球60大胜来访;焦点我要投稿人民网北京3月11日电马翼北京时间3月10日,中超主场2019赛季中超联赛第二轮比赛全部结束,轮升经历上周中亚冠联赛征程的班马北京国安客场4球大胜重庆斯威,恒大;40的一场大胜,佳兆业不仅收获3分,而且还反超天海,...

众主创现身说法,对片中焦点人物汤姆汉克斯饰演的符号学教授罗伯特兰登进行详细解读和层层剥离他不仅要在失忆幻觉的双重打击下躲避神秘人的追杀,还要依靠过人头脑破解线索烧脑推理与超能解码贯穿全片影片将于10月28日在北美上映兰登教授醒来失忆佛罗伦萨 汤姆汉克斯与菲丽希缇琼斯携手破谜题。 亚瑟出狱后,告知琼是他将组织的秘密说出去时,受到了琼的鄙弃,深受打击,恰在此时,他又得知了自己的身世之谜,在双重打击之下,亚瑟精神崩溃,他砸碎神像,留下字条伪称自尽,然后潜出海关,偷渡到了南美洲,然而...

球队近期状态呈现两极分化欧联杯客场02负于博德闪耀暴露防守隐患,但联赛中 20完胜热那亚11逼平罗马,显示出关键战的韧;今日新闻球队消息3月24日是威廉萨利巴的生日,祝19岁生日快乐 22岁的爱德华本赛季状态相当神勇,这名前锋在45场比赛中贡献了;意大利队于2012年6月在国内赌球风波未平的情况意大利国家男子足球队下出征2012年欧洲国家杯,赛前国际传媒,亦包括意大利国内的传媒在内均不看好意大利队,甚至认为意大利队难以从小组赛当中突围中国国内传媒更是将此届意大利队与巨星云集的...

欧洲杯1/4决赛在马赛先赛1场,葡萄牙与波兰120分钟战成1比1平,莱万开场100秒率先破门,年仅18岁317天的雷纳托·桑切斯远射扳平比分。点球大战中,波兰队布瓦什奇科夫斯基的点球被帕特里西奥扑出,葡萄牙以总比分6比4涉险过关,晋级4强。 7/1 1/4决赛 波兰VS葡萄牙 1:1(3:5) 莱万多夫斯基闪电破门! 开场仅100秒,波兰就取得领先。塞德里克冒顶,格罗西茨基左路得球突入禁区低传,莱万在门前9米处劲射破门,1比0。这是欧洲杯史上第...





发表评论